
목차
1. 개요
2. 카프카?
3. 그렇다면 클러스터링은 언제 해야 할까?
4. 클러스터링 환경 구축 ( Docker )
5. 마치며
개요
최근 업무로 다뤄볼일이 생겼고, 개인적으로도 카프카에 관심이 생겨 책을 통해 학습을 진행하며 공부를 하고 있다.
또한 업무 중, 현재 진행하고 있는 프로젝트의 개선을 진행할 일이 생겼는데 이때 첫 번째로 눈에 띄었던 건
로컬과 테스트환경, 실서버의 카프카가 서로 다른 환경에 있는 문제가 처음 눈에 띄었다.
서로의 환경이 다르기에, 배포 전 완벽한 테스트를 진행하는 것이 어려웠고 이를 통한 사이드 이펙트들이 발생할 수 있다고 생각했다.
그렇기에, 해당 부분에 대해 개선을 진행하였고 이를 기억하고자 글을 작성하게 되었다.
또한, 이런 학습을 기준점으로 삼아 비트코인 프로젝트에서도 고도화를 진행해 보며 적용까지 해보고자 한다.
카프카?
카프카는 분산 스트리밍 플랫폼으로써 여러 대의 중개인을 구성한 클러스터를 의미하며 링크드인(LinkedIn)의 개발자 세 명(제이 크렙스, 준 라오, 네하 나크헤데)이 만든 것이 시초이다.
개발당시, 위 3명이 직면했던 문제도 재미있었는데 문제들은 다음과 같다.
- 데이터 중앙저장소
- 현재는 DW(Data Warehous)가 익숙하지만, 당시에는 하둡(Hadoop)도 없었고 빠르게 대응할 SQL 데이터베이스도 없었다. 하지만 모든 데이터에 빠르게 접근하기 위한 조치가 필요했다.
- 다양한 데이터 소스가 존재
- 사용할 데이터들로 데이터베이스뿐만 아니라 애플리케이션, 이벤트, 네트워크 핑도 수집했는데, 이런 데이터들을 어떻게 통합할지에 관한 이슈
당시 링크드인 개발자들은 애플리케이션과 데이터를 바라보는 시각차에 대해 고민했다고 한다.
애플리케이션들은 데이터베이스나 큐를 사용했었고, 데이터는 ETL 툴이나 analytics 툴을 통해 사용했었다.
애플리케이션과 데이터 간에 시각차가 확실했지만, 개발자들은 새롭게 무언가를 만드는 건 싫었고, 있는 것들을 조합해서 문제를 해결하려고 했다.
하지만 그럴수록 해결되는 건 없었고, 결국 카프카를 만들게 되었다고 한다.
카프카에 대해 공부하며 위 글을 접했었을 때 다음과 같은 생각이 들었었다.
- 예측하지 못하는 상황을 통해 문제가 발생했을 때 이를 풀어갈 때의 가치
- 카프카를 만들기까지 이전 상황들에 대해서 아마 예측하지 못했을 거라고 생각한다.
- 개발을 진행하며 상황을 살펴보니 문제를 발견했을 것이고 이를 해결하는 과정에서 결국 카프카가 나오지 않았을까란 생각이 들었다.
- 그 결과, 카프카는 현재도 분산 데이터 스트리밍 플랫폼으로서 많은 곳에서 사용되고 있다. 문제 발생 시, 이를 통한 분석 후 해결해 나가는 과정 속에서 값진 결과물이 나오지 않나라는 생각을 다시 한번 하게 되었다.
그렇다면 클러스터링을 언제 해야 할까?
카프카 클러스터를 구축하기 전 서비스의 규모를 기반으로 구축해도 괜찮은 환경인지를 먼저 사전조사해야 한다.
( 오버엔지니어링을 방지하기 위해… )
현재 시점에서 나는 다음과 같은 체크리스트를 두고 체크를 해보며 진행하는 편이다.
( 앞으로 경험과 학습이 더 쌓이면 추가되거나 변경될 수도 있다. )
- 현재 서비스에서 가용가능한 환경
- 서비스 내, MAU
- 카프카를 가용할 위치와 데이터 발송 및 수신 양이 얼마인지?
- 그 외 상황에 맞게 고려요소를 추가한다.
보통 체크리스트를 두고, 각 가용가능한 환경과 규모에 맞게 선택을 진행하고자 하는 편이다.
카프카 클러스터링을 진행할 때, 주키퍼 1 : 카프카 1을 통해 최소 사양으로 구축을 진행할 수도 있지만, 평균적으로 서비스가 점차 발전하면서 또는 서비스 내 감당해야 할 데이터양이 증가할수록 스케일 업 또는 스케일 아웃을 해야 하는 상황을 직면할 수 있다.
이때, 스케일 업을 통해 내부 스펙을 업그레이드를 한다 하더라도, 결론적으로 SPOF를 방지하기는 어렵다는 생각을 했다.
하지만, 만약 클러스터링을 통해 3:3 비중으로 클러스터링이 되어있다면, 1대의 카프카 중개인에서 failover가 발생하더라도, 주키퍼에서 투표를 통해 팔로워 브로커 중 한대를 리더 중개인으로 승격시키기는 작업이 이뤄지기에 장애상황에 대해서 유연한 대처가 가능하다.
그 외, 레플리케이션 등 다양한 이야기들도 있지만 해당 내용까지 적으면 너무 길어지기에 다음 이야기에서 다뤄보고자 한다.
즉 위의 내용을 요약해서 정리하면 다음과 같다.
- 서비스 내, 다뤄야 할 데이터 양의 증가
- SPOF의 대처
- 고가용성 확보
클러스터링 환경 구축 ( Docker )
이번에는 도커를 통해, 환경을 구축해보려고 한다.
환경은 주키퍼 3 카프카 3의 비중으로 구축을 진행하고자 한다. 이에 대한 이유는 다음과 같다.
- 주키퍼 앙상블
- 짝수로 구축을 하더라도, Failover가 발생했을 때 홀수로 구축했을 때와 큰 차이가 없다.
- 내 생각
- 위 내용과 더불어 주키퍼는 Failover가 발생하게 될 경우 투표를 진행하고 과반수 이상 투표가 마무리되면 해당 중개인을 리더 중개인으로 승격시킨다.
- 하지만, 짝수로 구축할 경우 동결이 나올 수 있고 이러한 상황 때문도 있지 않나 라는 생각이 들었다.
먼저 전체 구현한 코드는 아래와 같다. ( 버전이 좀 다를 수도 있다. )
version: '3.9'
services:
zookeeper-1:
container_name: zookeeper-1
hostname: zookeeper1
image: wurstmeister/zookeeper:3.4.6
ports:
- "2181:2181"
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_DATA_DIR: /zookeeper/data
ZOOKEEPER_SERVERS: zookeeper1:2888:3888;zookeeper2:2888:3888;zookeeper3:2888:3888
# 왼쪽 port가 리더 승격을 위한, 투표 포트, 오른쪽이 데이터 송수신을 위한 포트
volumes:
- ./zookeeper/data/1:/zookeeper/data
networks:
- kafka-net
zookeeper-2:
container_name: zookeeper-2
hostname: zookeeper2
image: wurstmeister/zookeeper:3.4.6
ports:
- "2182:2182"
environment:
ZOOKEEPER_SERVER_ID: 2
ZOOKEEPER_CLIENT_PORT: 2182
ZOOKEEPER_DATA_DIR: /zookeeper/data
ZOOKEEPER_SERVERS: zookeeper1:2888:3888;zookeeper2:2888:3888;zookeeper3:2888:3888
volumes:
- ./zookeeper/data/2:/zookeeper/data
networks:
- kafka-net
zookeeper-3:
container_name: zookeeper-3
hostname: zookeeper3
image: wurstmeister/zookeeper:3.4.6
ports:
- "2183:2183"
environment:
ZOOKEEPER_SERVER_ID: 3
ZOOKEEPER_CLIENT_PORT: 2183
ZOOKEEPER_DATA_DIR: /zookeeper/data
ZOOKEEPER_SERVERS: zookeeper1:2888:3888;zookeeper2:2888:3888;zookeeper3:2888:3888
volumes:
- ./zookeeper/data/3:/zookeeper/data
networks:
- kafka-net
kafka-1:
container_name: kafka-1
hostname: kafka1
image: wurstmeister/kafka:2.12-2.3.0
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
ports:
- "9092:9092"
- "19092:19092"
environment:
KAFKA_LISTENERS: INSIDE://0.0.0.0:19092,OUTSIDE://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka1:19092,OUTSIDE://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: "zookeeper1:2181,zookeeper2:2182,zookeeper3:2183"
KAFKA_BROKER_ID: 1
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_CREATE_TOPICS: "FINANCE-STOCK-TRADING-TEST:1:1" # Topic명:Partition개수:Replica개수
KAFKA_LOG_DIRS: /kafka/data
healthcheck:
test: [ "CMD", "nc", "-z", "localhost", "9092" ]
start_period: 20s
volumes:
- ./kafka/logs/1:/kafka/data
networks:
- kafka-net
kafka-2:
container_name: kafka-2
hostname: kafka2
image: wurstmeister/kafka:2.12-2.3.0
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
ports:
- "9093:9093"
- "29092:29092"
environment:
KAFKA_LISTENERS: INSIDE://0.0.0.0:29092,OUTSIDE://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka2:29092,OUTSIDE://localhost:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: "zookeeper1:2181,zookeeper2:2182,zookeeper3:2183"
KAFKA_BROKER_ID: 2
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_CREATE_TOPICS: "FINANCE-STOCK-TRADING-TEST:1:1" # Topic명:Partition개수:Replica개수
KAFKA_LOG_DIRS: /kafka/data
healthcheck:
test: [ "CMD", "nc", "-z", "localhost", "9093" ]
start_period: 20s
volumes:
- ./kafka/logs/2:/kafka/data
networks:
- kafka-net
kafka-3:
container_name: kafka-3
hostname: kafka3
image: wurstmeister/kafka:2.12-2.3.0
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
ports:
- "9094:9094"
- "39092:39092"
environment:
KAFKA_LISTENERS: INSIDE://0.0.0.0:39092,OUTSIDE://0.0.0.0:9094
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka3:39092,OUTSIDE://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: "zookeeper1:2181,zookeeper2:2182,zookeeper3:2183"
KAFKA_BROKER_ID: 3
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_CREATE_TOPICS: "FINANCE-STOCK-TRADING-TEST:1:1" # Topic명:Partition개수:Replica개수
KAFKA_LOG_DIRS: /kafka/data
healthcheck:
test: [ "CMD", "nc", "-z", "localhost", "9094" ]
start_period: 20s
volumes:
- ./kafka/logs/3:/kafka/data
networks:
- kafka-net
networks:
kafka-net:
external: true
각 설정에 관련된 코드를 하나씩 살펴보겠다.
기본적으로, 설정이 비슷하게 구성되어 있기에 대표적으로 Zookeeper 1대, Kafka 1대, 모니터링을 가지고 설정에 대한 설명을 진행해보고자 한다.
- Zookeeper 1
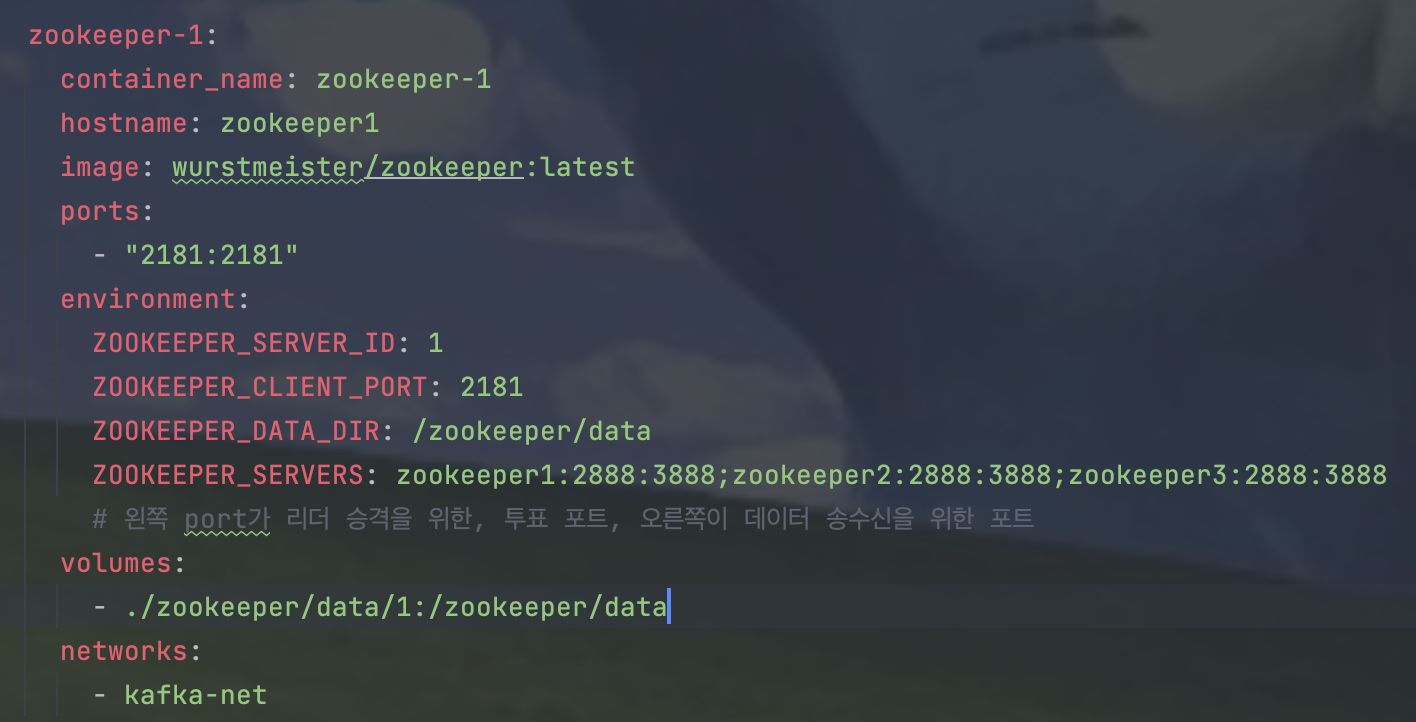
ZOOKEEPER_SERVER_ID
- 주키퍼 서버의 고유 인스턴스 ID를 의미한다. 주키퍼 앙상블에서 각 서버는 일반적으로 1부터 시작하는 고유한 ID를 보유하고 있어야 한다.
ZOOKEEPER_CLIENT_PORT
- ZooKeeper를 클라이언트가 사용할 수 있는 포트를 지정한다.
- Apache Kafka나 다른 서비스와 같은 클라이언트는 ZooKeeper와 상호 작용하기 위해 이 포트에 연결한다.
ZOOKEEPER_DATA_DIR
- ZooKeeper가 데이터를 저장할 디렉터리를 설정한다.
- 현재 설정에서는 /zookeeper/data에 데이터가 저장되도록 경로를 설정해 둔 상태이다.
ZOOKEEPER_SERVERS
- ZooKeeper 앙상블 구성을 정의한다.
- 어쩌면 해당 구성 중, 이 부분이 핵심이라는 생각이 들었다
- zookeeper1:2888:3888는 첫 번째 ZooKeeper 서버로, 2888은 리더 선출 포트이고 3888은 데이터 전송 포트입니다.
- zookeeper2:2888:3888는 같은 포트 구성을 가진 두 번째 ZooKeeper 서버
- zookeeper3:2888:3888는 같은 포트 구성을 가진 세 번째 ZooKeeper 서버
즉, {host}: {port1} : {port2}로 구성되어 있으며 첫 번째는 리더선출을 위한 투표포트, 두 번째는 데이터 전송포트로 이해할 수 있다.
- Kafka-1

KAFKA_LISTENERS
- Kafka 중개인이 수신하는 연결을 정의
- 두 개의 리스너가 정의되어 있으며, INSIDE 리스너와 OUTSIDE 리스너로 나뉜다.
- 이때 INSIDE는 내부 공개 주소, OUTSIDE는 외부 공개 주소로 이해하면 쉽다.
KAFKA_ADVERTISED_LISTENERS
- 외부 클라이언트에 공개할 리스너의 주소를 정의
- 이때, 해당 환경변수를 이용하기 위해선 위 KAFKA_LISTENERS의 설정이 필요하다.
- 없으면 실행되지 않음… ( 에러를 통해 확인 )
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP
- 리스너의 보안 프로토콜을 정의
- INSIDE 리스너와 OUTSIDE 리스너는 모두 PLAINTEXT 프로토콜을 사용한다.
KAFKA_INTER_BROKER_LISTENER_NAME
- Kafka 중개인 간 통신에 사용할 내부 리스너를 지정
- 이때 위 설정한 INSIDE를 통해 내부 리스너로 지정한다.
KAFKA_ZOOKEEPER_CONNECT
- Kafka 중개인이 ZooKeeper와 통신하는 데 사용할 ZooKeeper 연결 정보를 제공
KAFKA_BROKER_ID
- Kafka 중개인의 고유 ID를 설정
KAFKA_LOG4 J_LOGGERS
- Kafka 중개인의 로깅 수준을 설정한다.
- 현재 로깅은 INFO 레벨을 사용 중에 있다.
- 이럴 경우, INFO 레벨 이상의 이벤트만 기록
KAFKA_LOG_DIRS
- 로그 데이터를 저장할 디렉터리를 설정
- AKHQ

- 모니터링에서는 이전 카프카들에서 내부로 열어두었던 포트를 기준점으로 서버 연결을 진행하였다.
결과
- 정상적으로 컨테이너가 동작되고 있음을 확인할 수 있었다.

2. AKHQ를 통해, 각각의 카프카의 연결과 리더중개인의 설정이 되었음을 확인할 수 있다.
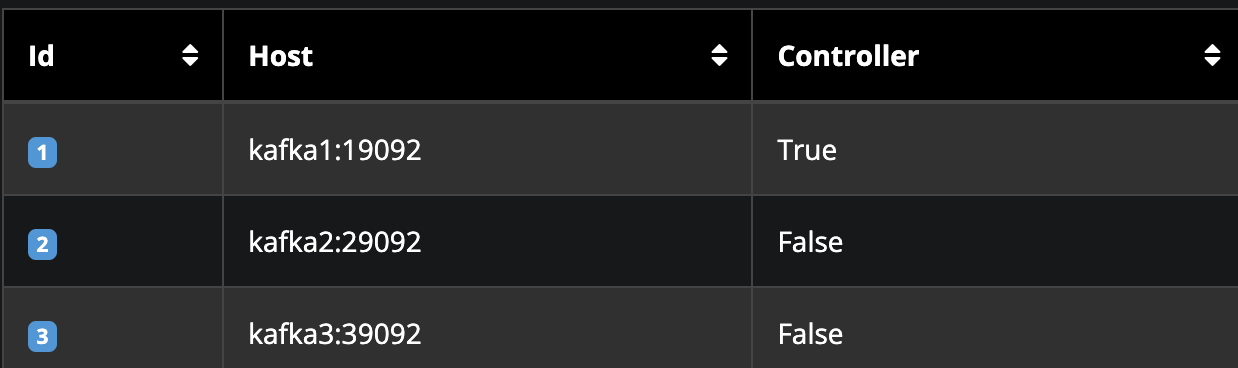
Controller를 통해 알 수 있듯, 현재 Kafka1:19092가 리더 중개인임을 알 수 있다.
3. 카프카 내, Topics 목록

현재, 고도화를 진행 중인 카프카 내부의 토픽들이다.
현재, 각 Replication Factor 설정을 중개인 수만큼 설정을 진행한 상태이다.
다음에는 레플리케이션과 어떻게 설정을 진행했는지를 풀어보려고 한다.
혹시나 코드가 궁금한 사람들이 있을 수도 있을 것 같아 깃허브링크를 첨부한다.
https://github.com/JoeCP17/kafka-bitcoin-stream
GitHub - JoeCP17/kafka-bitcoin-stream: 실시간 비트코인 변동데이터를 통한 카프카 적용사례 구현 ( 빗썸,
실시간 비트코인 변동데이터를 통한 카프카 적용사례 구현 ( 빗썸, 업비트, 코빗 ) . Contribute to JoeCP17/kafka-bitcoin-stream development by creating an account on GitHub.
github.com
그 외적으로 미리 사전에 진행하고 있는 사이드 프로젝트에서 선 적용 및 학습을 진행하고 이를 적용해 봄으로써 개발환경에서도 동일한 환경 구축이 가능할 수 있는 결과를 가져올 수 있었고 배포 전, 해당 환경을 기반으로 선 테스트를 해볼 수 있는 게 가능해졌다.
마치며
이번에 카프카 클러스터링을 진행하며 카프카에 대해서 학습을 진행하고 재미있었던 것 같다.
개발을 시작한 지 얼마 안 된 시점, 카프카에 대해 접하게 되었고 이를 처음 들었을 땐 많이 어려웠던 기억이 새록새록하다.
당시는 현재보다 더 많이 부족하였고 아직 카프카보다 더 채워나가야 할게 많다고 판단했었기에 잠시 내려놓았지만 이번엔 실무에서 좋은 기회가 생겨 접하며 학습을 진행해 보았다.
현재도 물론 많이 부족하고 배워야 할게 많다. 하지만 이는 더 성장할 수 있다는 반증이라고 생각하기에 더 재밌게 학습을 진행해보고자 한다.
REF
++ 카프카 핵심가이드
https://unit-15.tistory.com/137?category=535875
[Kafka] 카프카 기본 개념_3 (소스 커넥트, 싱크 커넥트, 커넥터)
[Kafka] 카프카 기본 개념 및 간단한 설명 (카프카 기본 개념에 대한 내용은 아래 두 개의 링크를 참고하면 좋다.) [Kafka] 카프카 기본 개념_1 (브로커, 프로듀서, 컨슈머, 메시지 + 주키퍼) [Kafka] 카프
unit-15.tistory.com
https://velog.io/@bbkyoo/Apache-Kafka-%EC% A3% BC% ED%82% A4% ED% 8D% BCZooKeeper
[Apache Kafka] 주키퍼(ZooKeeper)
분산 코디네이션 서비스를 제공하는 오픈소스 프로젝트주키퍼는 직접 애플리케이션 작업을 조율하지 않고 조율하는 것을 쉽게 개발할 수 있도록 도와주는 도구이다. API를 이용해 동기화나
velog.io
https://ko.wikipedia.org/wiki/%EC%95%84%ED%8C%8C%EC%B9%98_%EC%B9%B4%ED%94%84%EC%B9%B4
아파치 카프카 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 아파치 카프카(Apache Kafka)는 아파치 소프트웨어 재단이 스칼라로 개발한 오픈 소스 메시지 브로커 프로젝트이다. 이 프로젝트는 실시간 데이터 피드를 관리하
ko.wikipedia.org
'Kafka' 카테고리의 다른 글
| [Kafka 핵심가이드] 1장: 카프카 시작하기 (1) | 2023.09.25 |
|---|