
목차
- 서론
- 동시성을 제어해야 하는 이유
- 동시성
- 네임드 락
- 분산 락
- 분산 락을 활용할때 Redis를 활용하는 이유
- Lettuce vs Redisson
- Redisson 내 tryLock()과 Semaphore
- 예제
서론
최근, DB관련 공부를 진행하며 이전부터 동시성을 제어할 수 있는 방법으로 LOCK을 사용할 수 있음을 알고 있었는데,
위 내용을 현재 제가 사용하고 있는 Spring Boot에 접목시켜 봄으로써 이에 대한 리마인드와 저의 생각들을 정리해 보고자 글을 작성하게 되었다.
동시성을 제어해야 하는 이유
동시성을 그렇다면 왜 제어해야 할까요?
동시성을 제어하지 않는다면 발생되는 이유는 다음과 같습니다.
- Race condition
- 두 개 이상의 스레드가 동시에 같은 데이터를 접근하여 값을 변경하고자 할 때, 데이터의 예상치 못한 변경이 발생할 수 있다.
- DeadLock
- 두 개 이상의 스레드가 서로의 작업이 완료될 때까지 기다리면서 결국 아무도 완료되지 않는 문제가 발생할 수 있다.
- Data corruption
- 두 개 이상의 스레드가 동시에 같은 데이터에 접근하여 값을 변경할 때, 예상치 못한 데이터의 변형이 발생할 수 있다.
위와 같은 문제를 방지하기 위해 동시성제어를 통해 보다 안정적인 서비스를 제공할 수 있습니다.
동시성
- 싱글 코어에서 멀티 스레드를 동작시키기 위한 방식으로, 멀티 태스킹을 위해 여러 개의 스레드가 번갈아가면서 실행되는 성질을 말한다.
→ 반례로 코틀린은 싱글스레드에서 코루틴을 이용하여 동시성을 만족할 수 있다.
→ 멀티 스레드로 동시성을 만족시킬 수 있는 것이지 동시성과 멀티 스레드는 연관이 없다. - 동시에 실행되는 것처럼 보이는 것
→ 멀티 코어에서 멀티 스레드를 이용하여 동시성을 만족할 경우에는 실제 물리적 시간으로 동시에 실행된다.
→ 싱글 코어에서 멀티 스레드를 이용해 동시성을 구현하는 일부 케이스에 대한 내용이다.
네임드 락 ( Named Lock )
네임드 락의 경우 MySQL에서 사용되는 락 방법 중 하나로서, 이름을 가진 메타 데이터 락이다.
이름을 가진 락을 획득 후, 해제될 때까지 다른 세션은 해당 락을 획득하지 못한다.
여기서 주의해야 할 점은, 트렌잭션이 만료되면 락이 자동으로 해제되지 않기에 락을 해제시켜 주거나 선점시간이 종료되어야 해제된다는 특징을 가지고 있다.
MySQL에서는 GET_LOCK()을 통해 락을 획득할 수 있고, RELEASE_LOCK()을 통해 해제될 수 있다.
네임드락(GET_LOCK)의 사용 용도는 주로 분산 락에서 사용된다.

다음 사진을 보며 설명을 이어가 보고자 한다.
해당 그림을 보면 Session-1 , Session-2가 Stock에 동시적으로 요청을 보낼 시, 이때 락을 Stock에 거는 것이 아닌, 별도의 공간에 Lock을 걸게 된다.
이렇게 Lock을 걸게 되면 Session-2는 Session-1이 ‘1’이라는 이름으로 LOCK을 걸게 된다면 Session-2는 Session-1이 해제된 이후에 LOCK을 획득할 수 있게 된다.
분산 락 ( distributed Lock )
자바 스프링 기반의 웹 애플리케이션은 기본적으로 멀티 스레드 환경에서 구동이 된다.
따라서, 여러 스레드가 함께 접근할 수 있는 공유 자원에 대해 Race condition이 발생하지 않도록 별도의 처리가 필요하다.
자바는 synchronized라는 키워드를 언어차원에서 제공하여, 모니터 기반의 상호배제 기능을 제공하게 된다.
하지만, 이런 메커니즘은 같은 프로세스에서만 상호 배제를 보장한다.
웹 애플리케이션 프로세스를 단 하나만 사용하는 서비스라면 상관없지만, 대부분 일반적으로 서버를 다중화하여 부하 분산 처리를 한다.
이러한 분산 환경 속에서 상호 배제를 구현하여 동시성 문제를 다루기 위해 등장한 방법이 바로 분산락이다.
여기서 알아야 할 사항은 분산락은 DB에서 제공하는 락의 종류가 아니다.
일반적으로 웹 애플리케이션에서 공유 자원으로 데이터베이스를 가장 많이 사용하기에, 데이터베이스에 대한 동시성 문제를 분산락으로 풀어내는 사례가 많을 뿐이다.
물론, DB의 락 기능을 활용하여 분산 락을 구현할 수 있지만, 직접적으로 연관 있다고 보기는 어렵다.
분산 락을 구현하기 위해 락에 대한 정보를 ‘어딘가’에 공통적으로 보관하고 있어야 한다. 그리고 분산 환경에서 여러 대의 서버들은 공통된 ‘어딘가’를 바라보며, 자신이 임계 영역(critical section)에 접근할 수 있는지 확인한다.
이렇게 분산 환경에서 원자성(atomic)을 보장할 수 있게 된다. 그리고 그 어딘가로 활용되는 기술은 MySQL의 네임드 락, Redis, Zookeeper 등이 있다.
분산 락을 활용할 때 Redis를 활용하는 이유
대체적으로 분산락을 Redis를 활용하여 많이 제어하고 있는데, 왜 그럴까?
- Redis의 Lock 구현의 여러 가지 기능들을 제공하기 때문이다.
- Redis는 원자성 작업을 지원하는 분산형 메모리 내 데이터 저장소이기에, 여러 노드에서 동기화해야 하는 잠금을 구현하는 데 적합하다.
- Redis는 잠금 시간 초과 및 기타 고급 잠금 동작을 구현하는데 사용할 수 있는 Pub / Sub 메시지와 Lua 스크립트를 지원한다.
Lettuce vs Redisson
Spring Boot에서는 Lettuce, Redisson을 활용하여 Redis 내 분산 락을 제어할 수 있다.
하지만, 대개로 Redisson을 많이 활용하는데 이유가 무엇이었을까?
- Lettue의 Lock은 setnx 메서드를 통해 사용자가 직접 스핀락 형태로 구성하게 된다.
- 락이 점유 시도를 실패했을 경우 계속 락 점유 시도를 하게 되고, 레디스의 부하를 일으키게 된다.
- Lettuce의 경우 만료시간을 제공하고 있지 않기 때문에, Redisson과는 다르게 만약 Lock을 잡고 있는 상태에서 장애가 발생할 경우 다른 서버들에서는 락을 점유할 수 없다.
Redisson 내 tryLock()과 Semaphore
Redisson 내부에서 락을 잡기 위해 사용되는 tryLock() 메서드 내부를 살펴보자
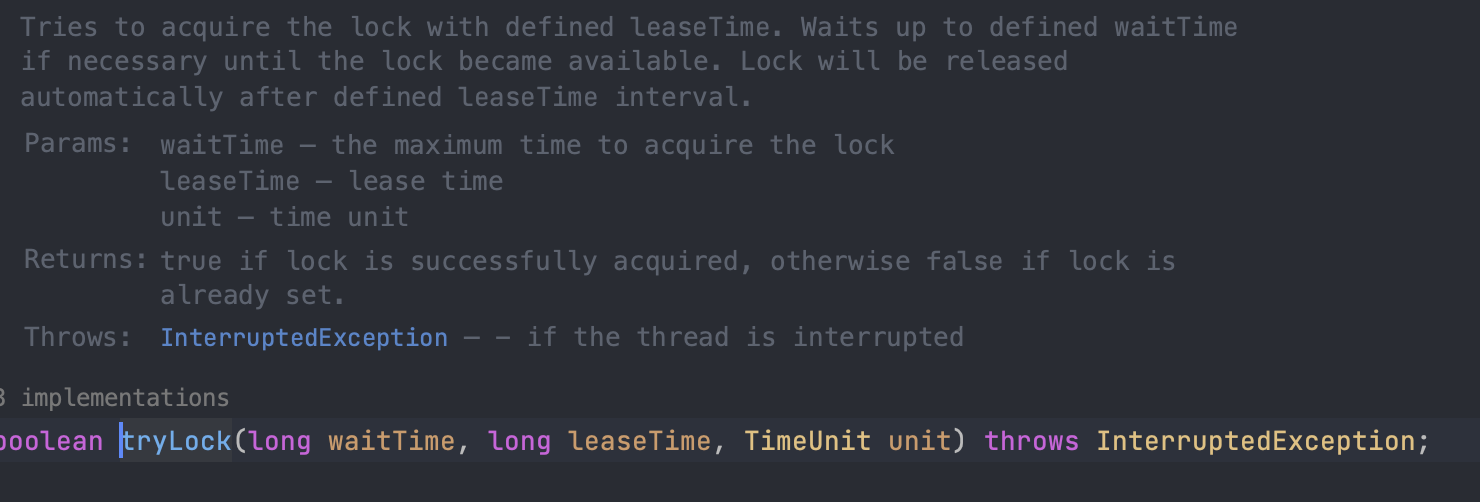
- waitTime : 락을 사용할 수 있을 때까지 기다리는 시간
- leaseTime : 시간이 지나면 락이 해제되는 시간
해당 메서드의 구현체를 살펴보겠다.
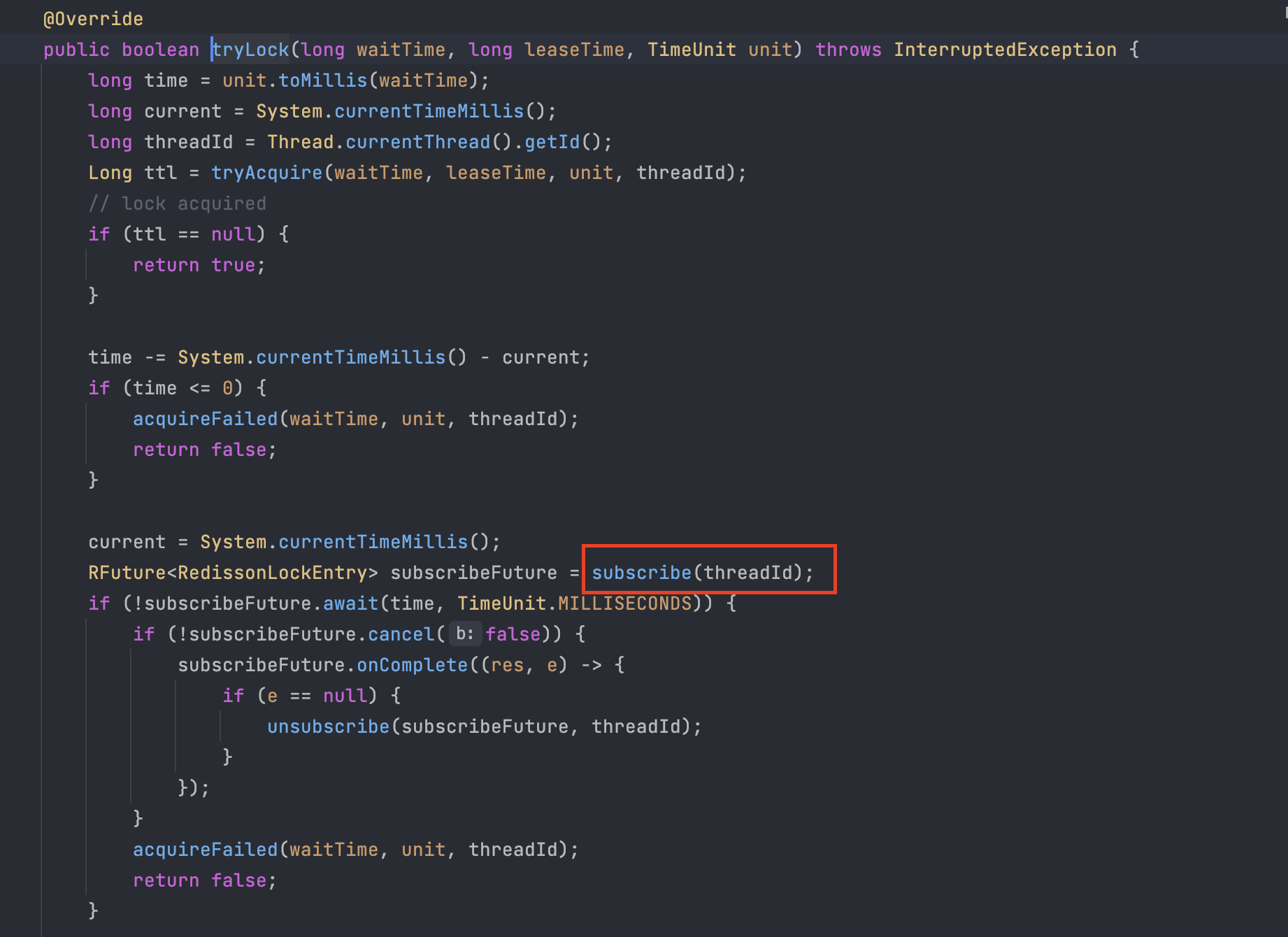

tryLock() 내부를 살펴보면 다음과 같이 subscribe 메서드를 찾을 수 있는데 이 메서드는 위 사진처럼 pub/sub 기능을 활용하고 있음을 확인할 수 있었다.
해당 메서드의 구독이 성공하게 될 경우 Redis 서버는 지정한 채널에 대한 메시지가 발행되는 경우 클라이언트에게 메시지를 전송하게 됩니다.
그렇다면 이 내부는 어떻게 구성이 되어있을까요?

다음 사진은 위 pubsub 내, subscribe 메서드 내부입니다.
해당 부분까지 확인하였을 때, tryLock()을 활용할 경우 위 내용처럼 Semaphore를 활용하고 있음을 확인하고 있었습니다.
그렇구나! 여기까지 살펴보았을 때 다음과 같은 플로우로 진행됨을 확인할 수 있었습니다.
- Redisson tryLock()을 호출할 시, subscribe 메서드 내부의 getSemaphore 메서드를 호출하여 서버와의 통신을 통해 세마포어를 가져옵니다.
- 그 후, acquire메서드를 호출하여 락을 획득하게 되는데 이때 지정된 시간 내 락을 얻을 수 있다면 true, 실패하면 false를 반환합니다.
Do-it 실습!
이제 해당 개념을 살펴보았으니, 예제를 통해 실습을 진행해 보았다.
동시성이 발생하는 시나리오를 다음과 같이 구상해 보았다.
- 아이유 콘서트 티켓이 발매되었다.
- 각 유저들이 한정된 티켓을 구매하기 위해 구매를 시도한다.
한번 위 상황을 고려하여 구현을 하였다. 내용이 너무 길어질 것 같아, 구현내용은 생략하고 테스트 코드를 통해 살펴보겠다.
Used Stacks
- Spring Boot
- Redis
- Redisson
해당 구현 내용은 깃허브 링크를 첨부합니다 :)
https://github.com/JoeCP17/spring-study/tree/master/lock
GitHub - JoeCP17/spring-study: 스프링 TIL 저장소
스프링 TIL 저장소. Contribute to JoeCP17/spring-study development by creating an account on GitHub.
github.com
마치며
DB에 대한 공부를 계속 진행해 보며 이전부터 건수님이 작성해 주셨던 분산락을 재미있게 읽고 이를 자세하게 공부해 보는 시간을 가져보았습니다. 🙂
해당 개념을 다시 한번 공부해보며 이전 RealMySQL에서 읽었던 각 Lock의 대한 개념들과 Redisson의 실행 구조와 왜 사용하는지에 대해 다시한번 공부를 할 수 있었던 좋은 시간이었습니다.
꼭 분산락이 아니더라도 Lock의 경우 정말 사용해야 할 경우가 아닌 경우에 사용하게 될 시, 성능저하의 이슈가 있을 수 있기 때문에 조금 더 심도 있게 고민해야 할 수 있음을 공부하며 다시 한번 느낄 수 있었습니다.
아직까지는 실무에 적용을 시켜볼 일이 없지만 앞으로의 일정들과 기획에 따라 사용해야 할 경우 접목시킬 수 있도록 더 갈고닦아야겠다고 생각했습니다.
Ref.
Redis로 분산 락을 구현해 동시성 이슈를 해결해 보자!
재고시스템으로 알아보는 동시성이슈 해결방법 - 인프런 | 강의
'Spring' 카테고리의 다른 글
| 빗썸 API를 활용한 매수 / 매도 데이터 적재 (1) | 2023.06.11 |
|---|---|
| [Spring Boot + Chat GPT] Open AI API 적용기 (1) | 2023.04.16 |
| Throttling과 debounce에 대해 알아보자 (0) | 2022.12.11 |
| [Design Pattern] Strategy Pattern 전략패턴에 대해 알아보자! (0) | 2022.10.30 |
| [DI,DIP] 의존성 주입에 대하여 (0) | 2022.10.12 |