

서론
최근 회사프로젝트를 접하며 새로 “코틀린 + Kafka”를 활용해야 하는 서비스의 개발을 진행해야 했고
개인적으로 코틀린과 kafka를 활용해 본 적이 없었기에 학습을 진행하며 이를 활용해 예제를 구현하고자 하였다.
나는, 그저 만드는 것보다 무언가 재밌는 주제를 선정해 해당 서비스를 개발해 보면 어떨까? 란 생각을 하였고
이때 눈에 들어왔던 게 비트코인 시세였다.
비트코인 시세는 실시간으로 변동이 되고 빗썸에서는 Open API를 통해 이에 대한 데이터를 제공해주고 있었다.
학습목적으로 사용하고자 했고, 영리 목적은 절대 네버 없기에 해당 API를 활용해 구현을 진행해 보면 재밌겠단 생각을 했고 해당 부분의 구현을 진행했다.
설계
해당 서비스의 구현을 진행하며 고려한 사항은 다음과 같았다.
- 빗썸 내 어떤 Open API를 사용해 데이터를 가져올지?
- 거래소 내 어떤 코인의 데이터를 가져올 것인지?
- 전반적인 서비스 Workflow는 어떻게 가져갈 것인지?
고려한 상황에 대한 답변들은 다음과 같다.
- 빗썸 내 어떤 Open API를 사용해 데이터를 가져올지?
- 투자자들 입장 ( 물론 나도 투자자 )에서 곰곰이 생각해 볼 때 시세가 빠르게 변하는 코인시장에서는 매도와 매수의 양을 보고 언제 들어가고 나올지 체크를 1차적으로 한다는 걸 풍문으로 들었던 적이 있었다.
- 해당 이야기에 의거하여 빗썸 내 코인의 매수 / 매도 데이터를 가져와 사용해 보기로 하였다.
- 거래소 내 어떤 코인의 데이터를 가져올 것인지?
- 해당 서비스를 통해 내가 원하는 코인의 데이터를 확인할 수 있도록 하기 위해, 가져오고 싶어 하는 코인을 등록하기 위한 API를 구현하여 등록된 코인 값만 가져와 활용할 수 있도록 설정하고자 했다.
- 해당 서비스를 통해 내가 원하는 코인의 데이터를 확인할 수 있도록 하기 위해, 가져오고 싶어 하는 코인을 등록하기 위한 API를 구현하여 등록된 코인 값만 가져와 활용할 수 있도록 설정하고자 했다.
- 전반적인 서비스 WorkFlow는 어떻게 가져갈 것인지?
- 간단하게 다음과 같이 흐름을 가져가고자 했다.
- 유저는 REST API를 통해 실시간으로 계속 확인하고 싶어하는 코인을 등록한다.
- Scheduled 어노테이션을 활용해 스케줄러가 등록된 코인 이름을 활용해 API에 매수 / 매도 가격을 요청해 데이터를 가져온다.
- 가져온 데이터를 Kafka를 통해 데이터 적재 서버에 전달한다.
- EventListener를 통해 큐에 값이 들어올 경우 해당 서버는 데이터를 받아 데이터베이스에 적재한다.
- 유저는 REST API를 통해 실시간으로 계속 확인하고 싶어하는 코인을 등록한다.
- 간단하게 다음과 같이 흐름을 가져가고자 했다.
해당 흐름을 기반으로 구성한 아키텍처는 다음과 같다.
Kafka를 학습하며 이에 대한 모니터링 툴 또한 존재한다는 사실을 알게 되었고 cmak과 akhq들 중 akhq를 사용해 모니터링을 진행했다.
akhq를 사용해 모니터링을 진행한 이유는 사실 아래와 같은 이유가 존재했다.
- 무료 오픈 소스로 제공되고 있어 간편하게 사용이 가능하다.
- 기본적인 브로커 데이터 리소스에 대한 모니터링 외 다양한 기능들을 제공한다.
- 실시간 모니터링
- 토픽 메시지 검색
- 토픽별 ACL 조회
- 연동 가능성
무엇보다 akhq는 별도의 jmx 포트에 대한 설정 없이도 컨슈머 그룹에 대한 모니터링이 가능하고 카프카 브로커 뿐만이 아닌 스키마 레지스트리와 커넥트 연결이 가능했기에 카프카에 더 안성맞춤이라는 점에서 akhq를 채택하게 되었다.
Docker Setting
해당 서비스를 구현하며 Docker를 활용하여 세팅을 진행했는데 현재 나는 다양한 환경에서 작업을 진행할 때가 많다. ( 개인용, 업무용, 공용 등 )
또한, 혹여나 해당 서비스가 필요하거나 그 외 사용하고 싶은 분들이 계실 때의 가능성을 높여 범용성 있게 가져가기 위해 세팅을 진행했었다.
세팅은 다음과 같다.
해당 예제에서는 Zookeper, Kafka를 각 1개씩 사용했는데 빗썸 API만을 활용해 서비스 구현을 생각했었기에 각 1개씩 사용했다.
만약 그 외의 API ( 업비트, 코빗 등의 암호화폐 거래소 )를 사용하게 된다면 각 API별로 하나씩 브로커를 두는 게 보다 서비스를 운용함에 있어 유용하다.
이유는 다음과 같다.
- 분리된 환경
- 각 거래소마다 독립적인 Kafka 클러스터와 ZooKeeper 앙상블을 유지하는 것은 환경을 분리하여 서로에게 영향을 주지 않도록 한다.
- 예를 들어, 한 거래소의 Kafka 클러스터나 ZooKeeper 앙상블에 장애가 발생해도 다른 거래소는 영향을 받지 않고 정상적으로 운영될 수 있다.
- 확장성
- 거래소별로 Kafka와 ZooKeeper를 독립적으로 운영하면, 각 거래소의 데이터 양과 부하에 맞게 확장할 수 있다.
- 각각의 Kafka 클러스터와 ZooKeeper 앙상블을 증가시켜 처리할 수 있는 데이터 양과 처리량을 늘릴 수 있다.
- 격리된 문제 해결
- 거래소별로 독립적인 Kafka와 ZooKeeper를 사용하면, 문제 발생 시 해당 거래소의 Kafka와 ZooKeeper에 집중하여 문제를 해결할 수 있다.
- 전체 시스템에 영향을 미치는 문제가 발생해도 다른 거래소의 운영에 영향을 주지 않으므로 문제를 해결하기가 더 효율적이다.
Kafka Producer
해당 부분에서는 핵심적으로 기능을 진행하는 부분들 위주로 살펴보고자 한다.
Producer의 경우 위 아키텍처 상 설명했던 내용과 같이, 등록된 코인 데이터를 읽고 해당 데이터를 통해 빗썸 사이트 내에서 매수 / 매도 가격을 읽어 kafka로 데이터를 전달한다.
Kafka Producer server config
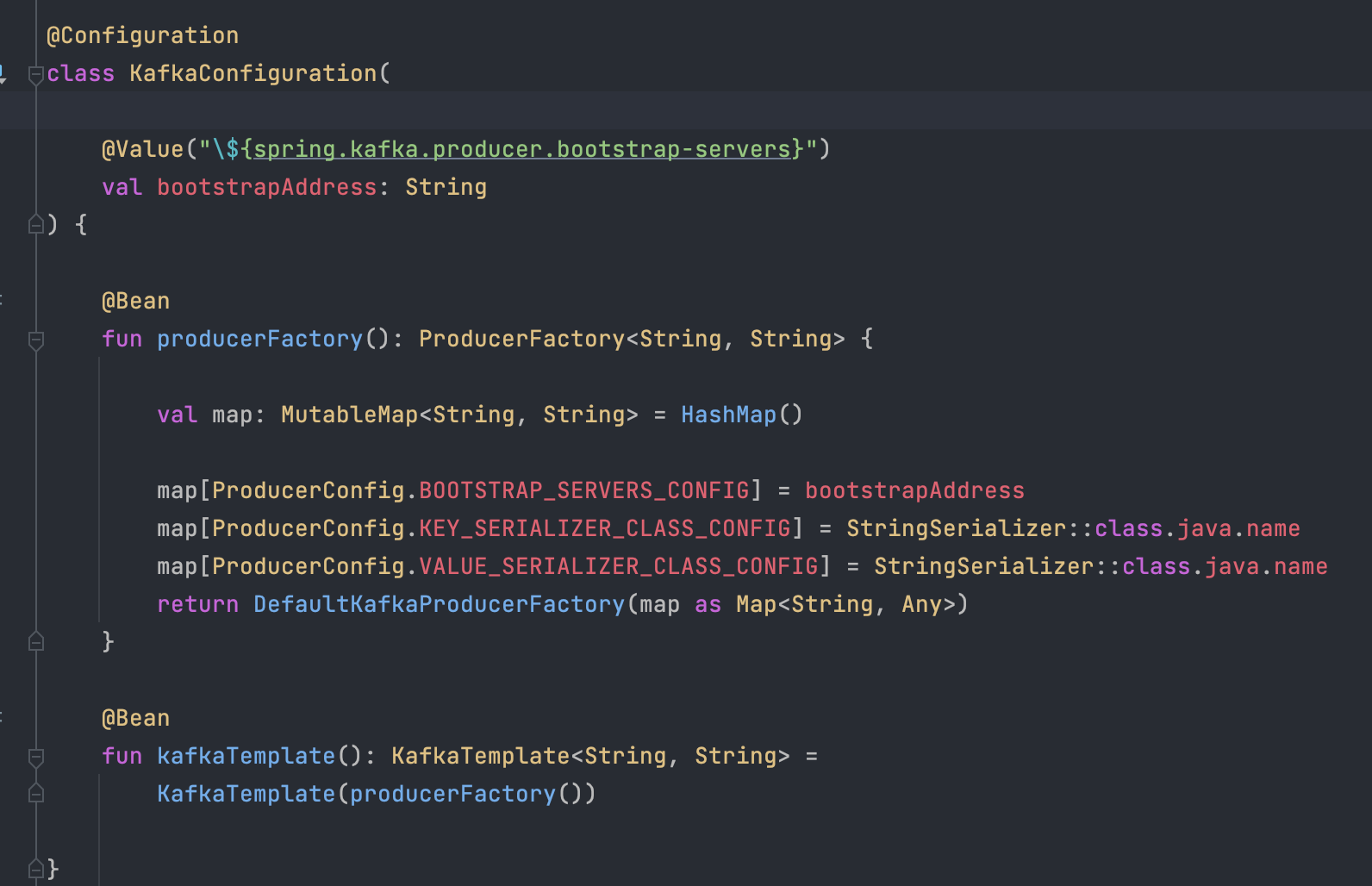
위 config는 producer 세팅이다.
해당 서버는 위 아키텍처상에 있던 것처럼 Data Server로의 Producer역할 외로 하는 내용이 없기에, consumer을 따로 두진 않았다.
producer.yml
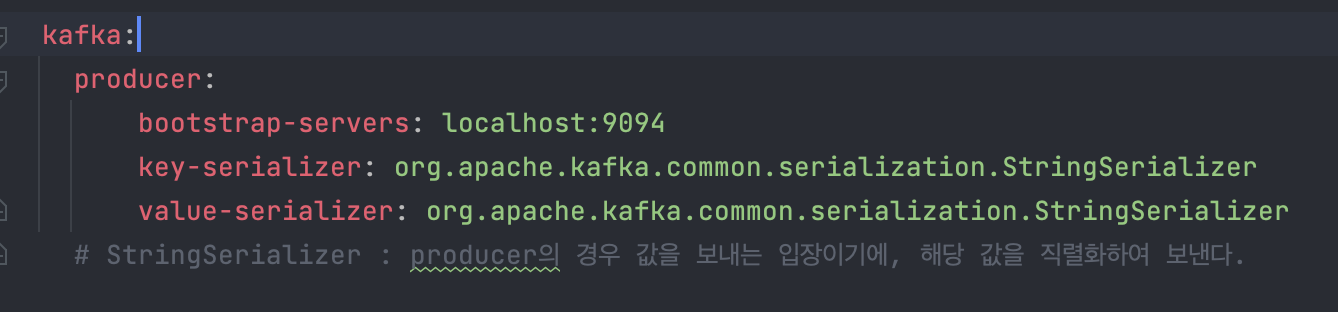
yml 내 설정은 다음과 같이 구성되어 있다.
Producer의 경우 kafka에 데이터를 넣을 때 Serializer를 통해 값을 전달하기에, 다음과 같이 세팅을 진행했다.
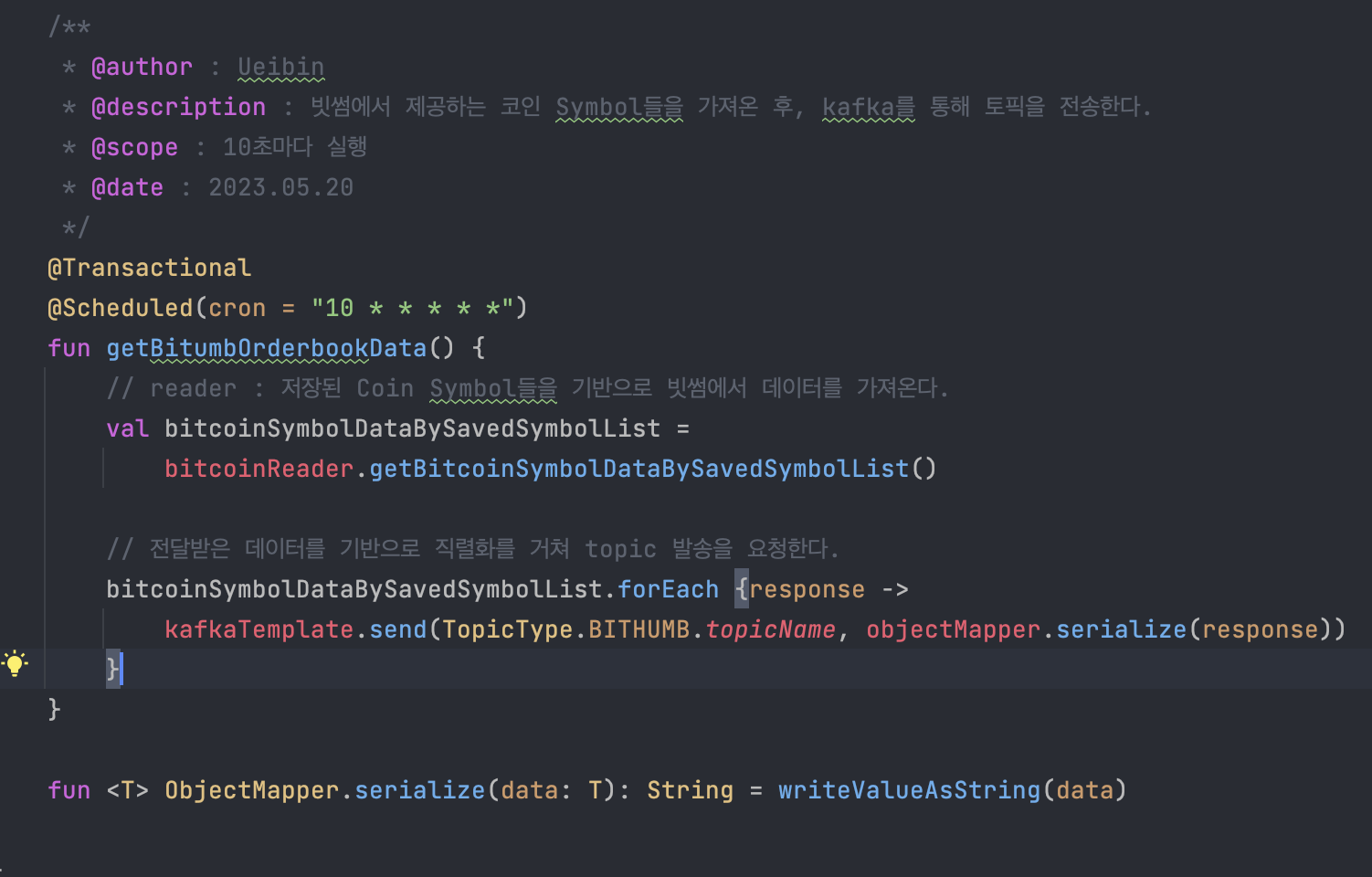
- reader
- 해당 부분의 경우 위에서 말한 것과 같이 데이터를 읽어오는 역할을 한다.
- 읽어오는 값의 경우 사용자가 등록한 코인의 이름이다.
- 그 후, kafka에 데이터를 요청한다.
ObjectMapper의 확장함수를 넣은 이유는 다음과 같다.
- 현재는 빗썸의 매수 / 매도 데이터 하나를 기반으로 넣었지만 추후 다른 데이터도 직렬화해야 할 경우를 위해서...
Kafka send 내부

해당 내부를 통해 알 수 있듯, 카프카에서 요청을 받아 보낼 때 key, value 형식으로 데이터 전달이 이뤄져 있음을 알 수 있다.
Kafka Consumer
다음은 데이터 요청을 받아 적재를 진행하는 consumer 서버의 세팅이다.
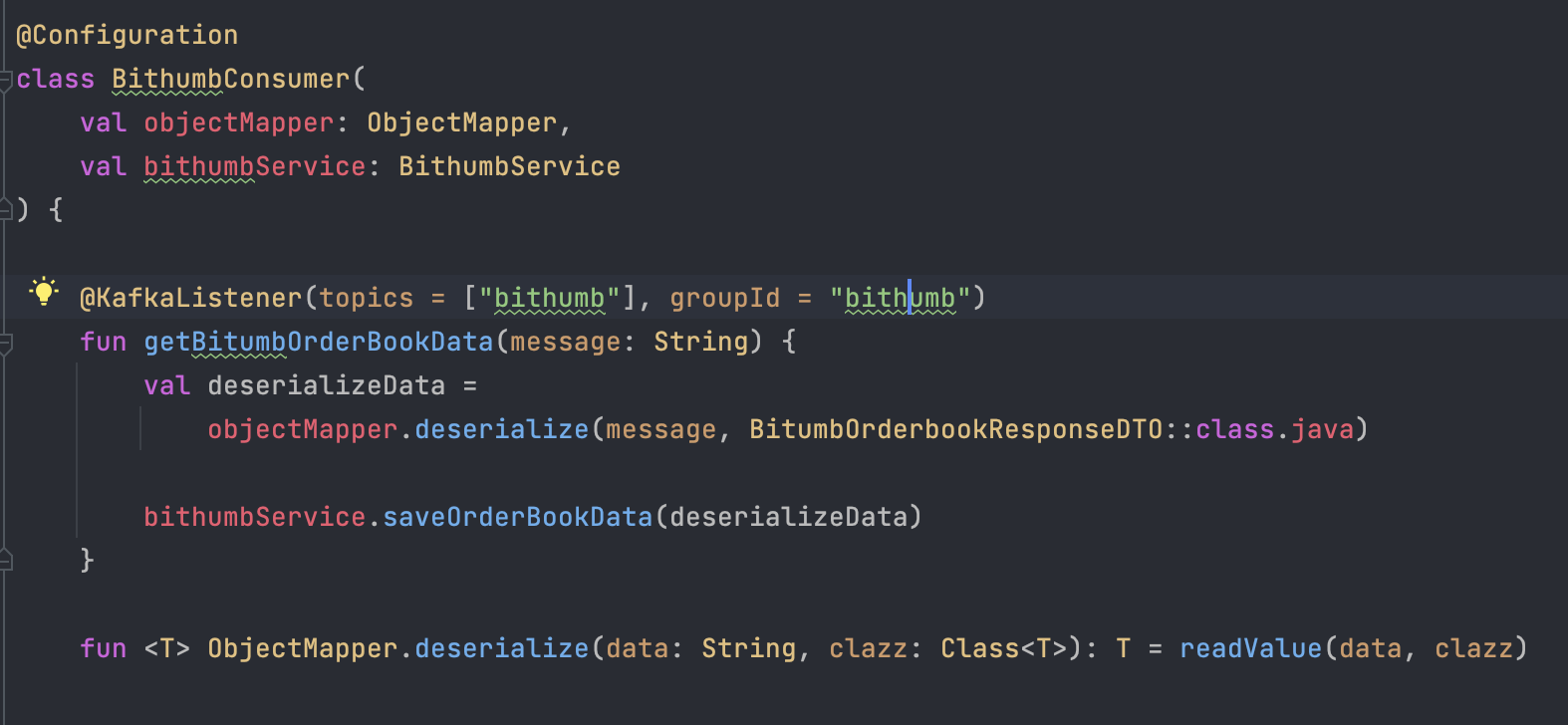
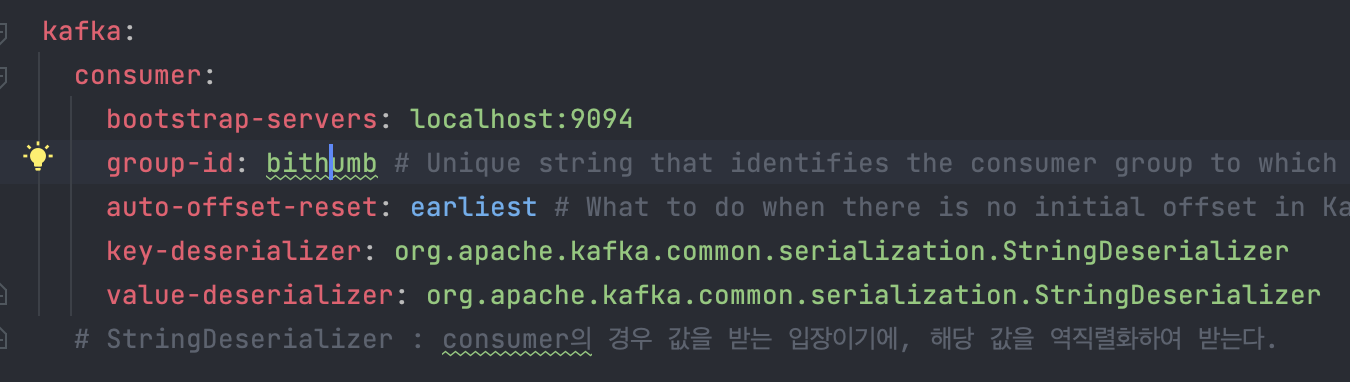
bithumb의 경우 Topic을 bithumb ( 가제 )로 설정하였었고
groupId 또한 bithumb으로 설정하였기에 해당 topic을 구독함으로써 이벤트가 발생 시 값을 받을 수 있도록 설정하였다.
Consumer.yml 내부
만약, 해당 토픽에 데이터가 들어올 경우 플로우는 다음과 같다.
- Topic에 이벤트가 발생한다.
- KafkaListener를 통해 데이터를 읽어온다.
- deserialize를 통해 읽어온 데이터를 데이터적재에 필요한 DTO 형식으로 맵핑을 진행한다.
- 그 후, 데이터베이스에 적재를 진행한다.
현재는 학습을 위해 매우 간단한 플로우로 구성하였지만 추후 더욱 확장하여 웹 페이지까지 한번 만들어 보고자 한다.
시연
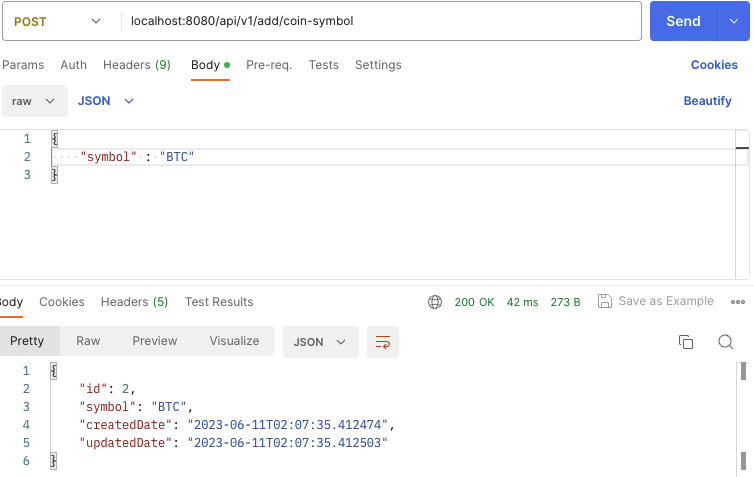
다음과 같이 Symbol를 등록한다.
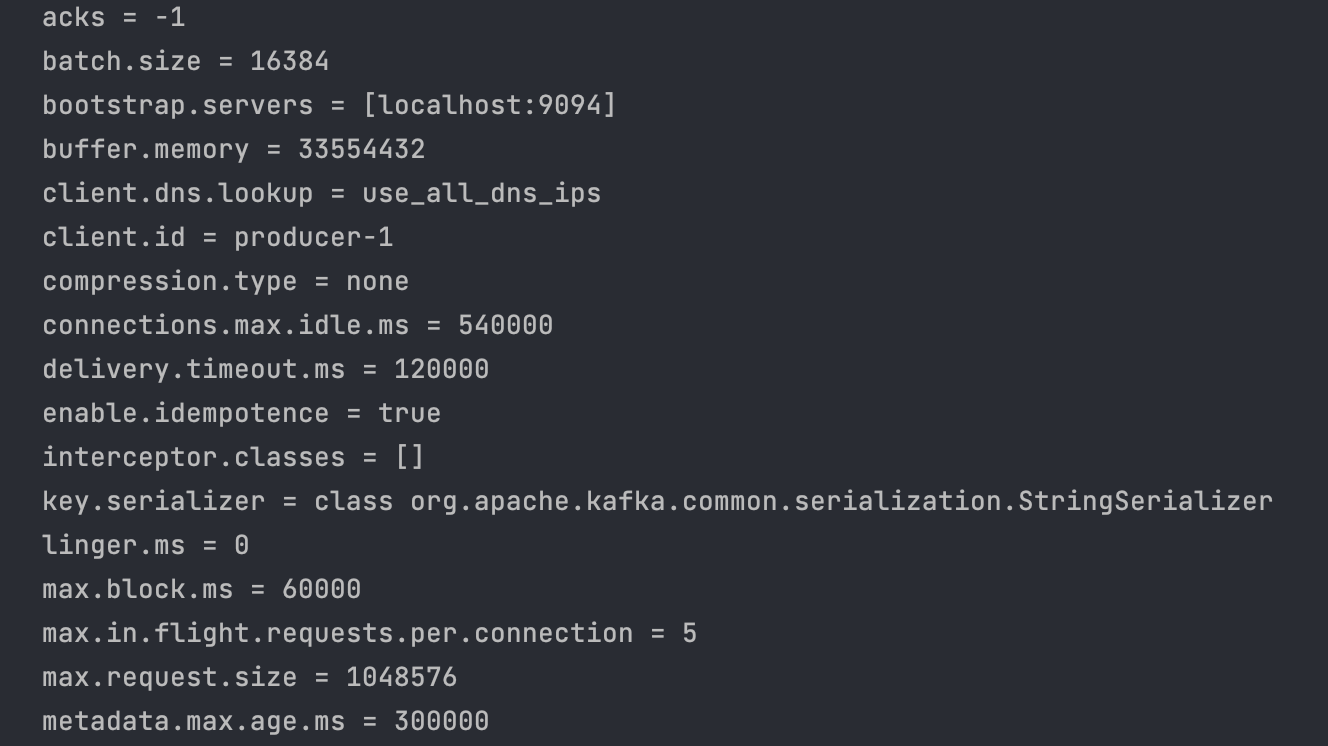
Producer 내 데이터 이동 관련 Log ( 일부 )
다음과 같이 등록된 값을 기반으로 빗썸 내 해당 토큰의 매수 / 매도 데이터를 가진 후 Queue에 전달한다.
akhq 내 값 확인
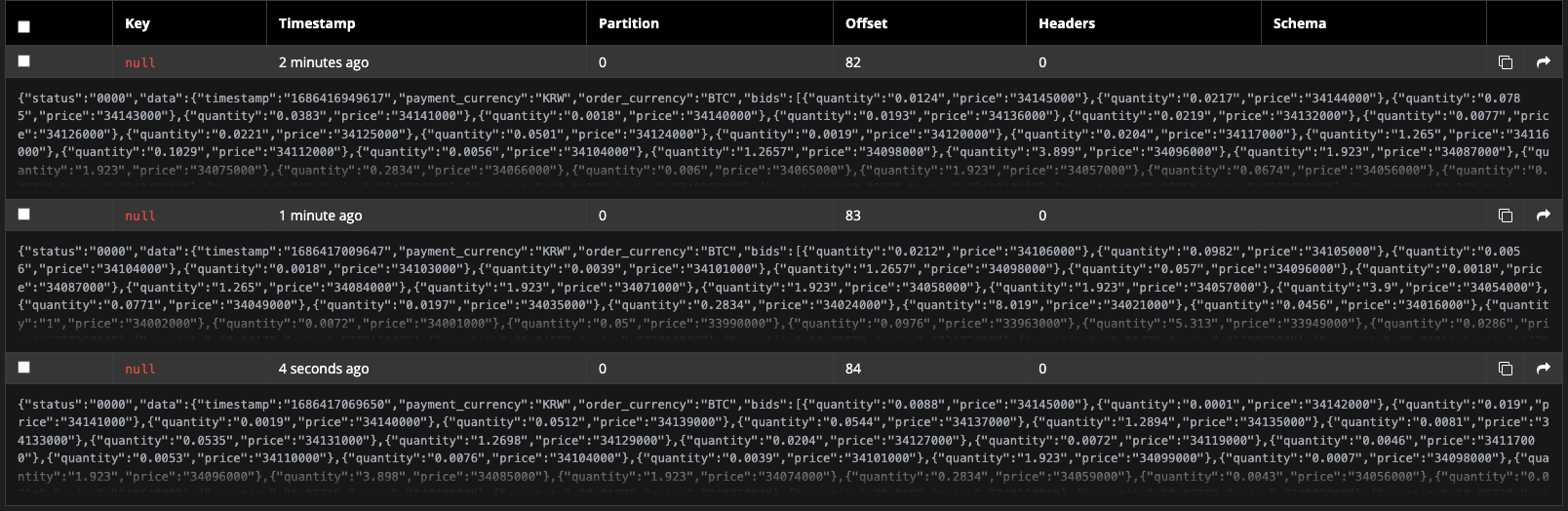
다음과 같이 모니터링 내, 값이 정상적으로 들어온 걸 확인할 수 있다.
Consumer Server 내 Listener Log ( 일부 )
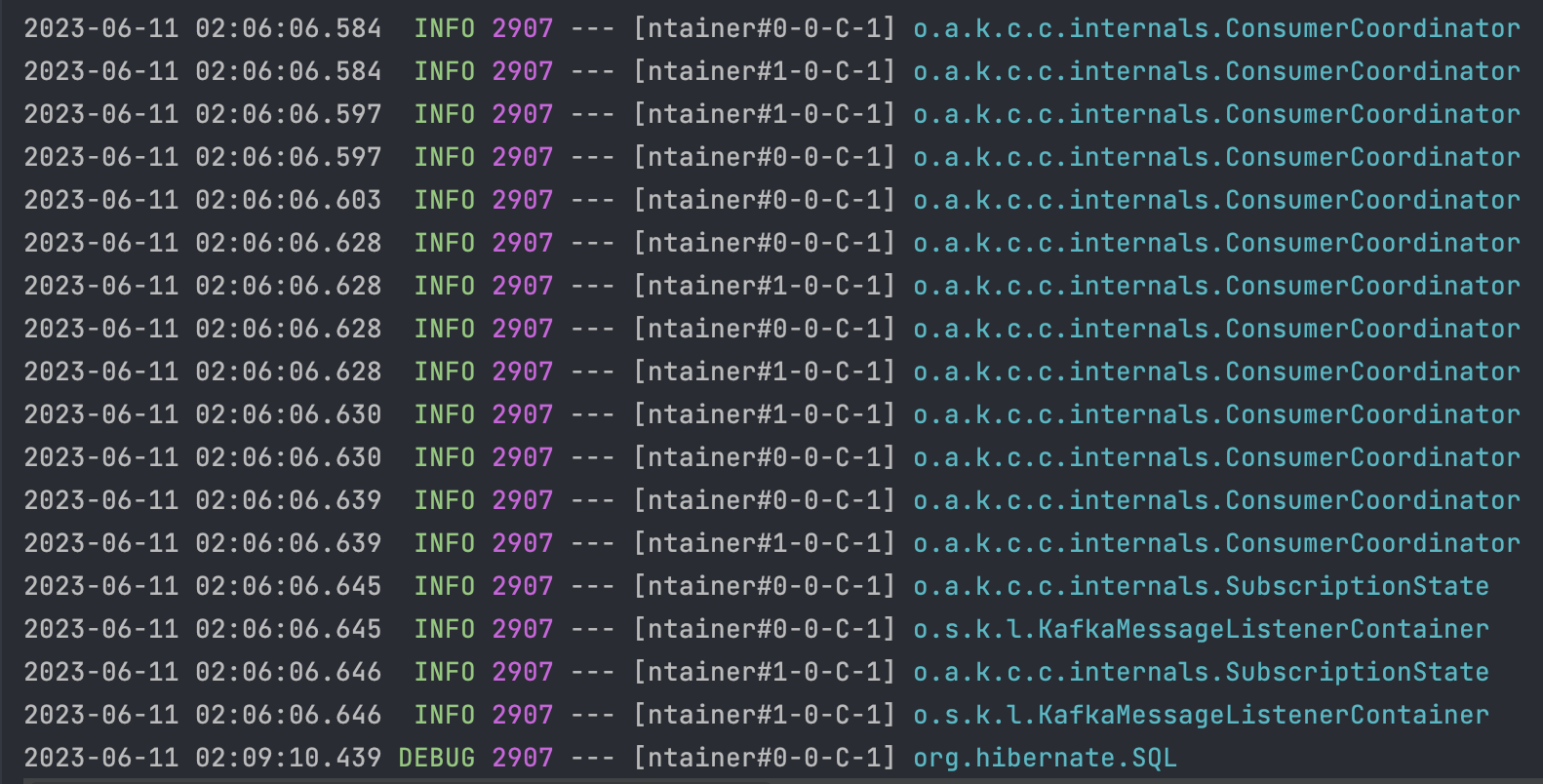
Consumer의 경우 지속적으로 값이 들어왔는지를 체크하고, 만약 값이 들어왔을 경우 데이터 적재를 진행한다.
데이터 적재 확인 ( 매도 데이터 )
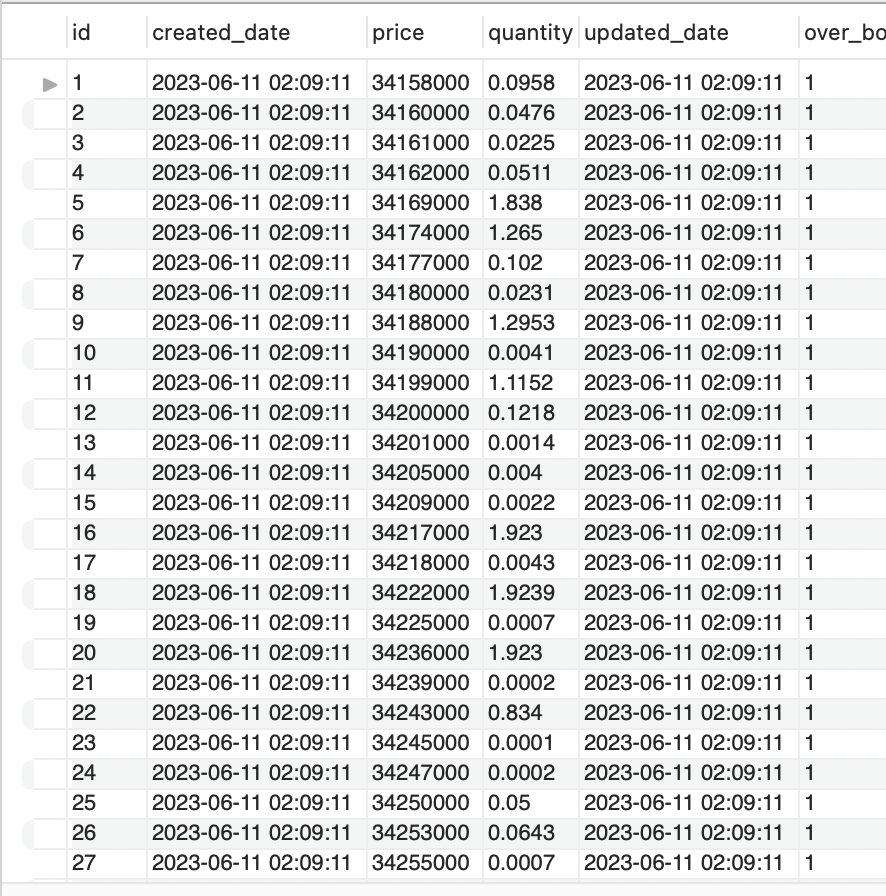
데이터 적재 ( 매수 데이터 )
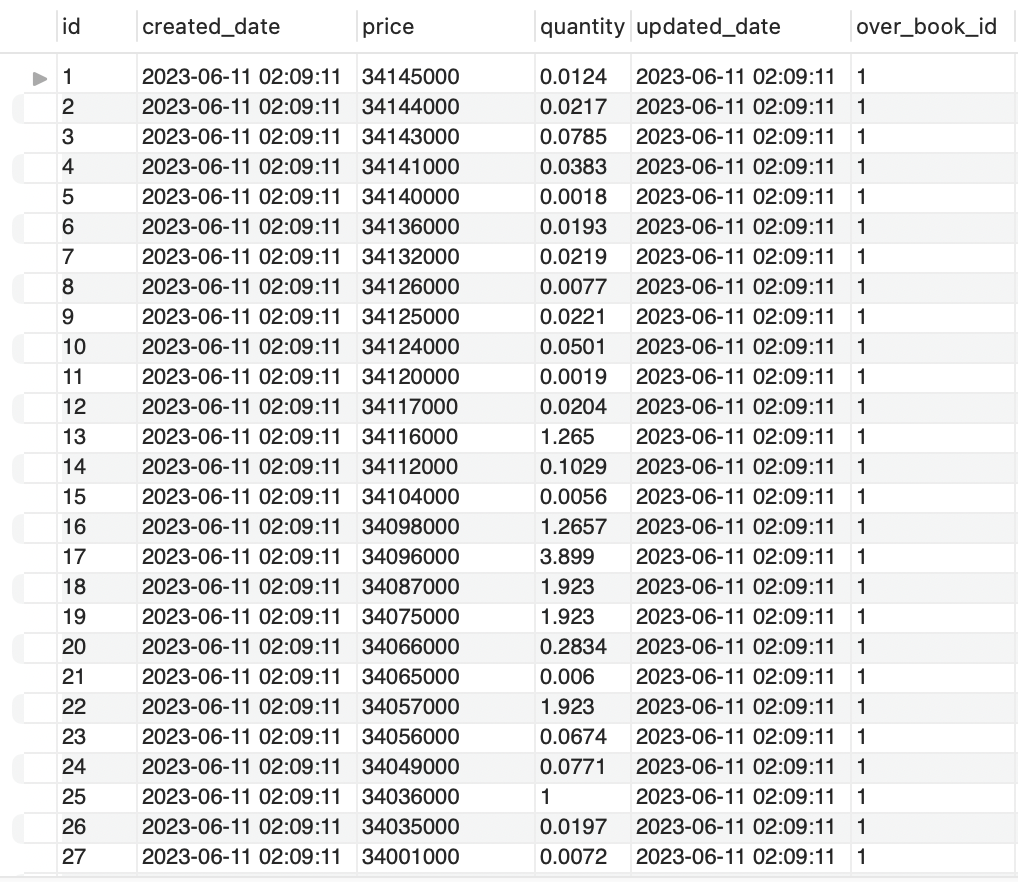
다음과 같이 정상적으로 데이터를 적재하고 있음을 알 수 있다.
마치며
이번에 좋은 기회를 얻어 Kafka에 대해 공부하고 이를 기반으로 실습까지 진행해 보았다.
해당 아티클에서 아직 다루지 못한 내용은 다음과 같다.
- Kafka 내 실패케이스에 대해
- Kafka Queue 내 데이터 바이트 관리
- Kafka에 대해
그 외적으로도 더 있지만 이를 기반으로 하나씩 천천히 풀어가 보고자 한다.
정말 간단한 예제일 수 있지만, 해당 부분의 멀티모듈 세팅과 구현까지 진행해 보며 추후 해당 프로젝트를 기점으로 실시간 데이터 변동 프로젝트까지 진행해보고 싶단 생각을 많이 받았다.
그렇기에, 해당 부분 구현을 마친 이후 실시간성에 대해 관심을 가지게 되었고 관련 콘퍼런스와 아티클을 찾아보며 공부를 진행하고 있다.
잘 마무리가 되어 조만간 또 흥미로운 주제로 글을 쓸 수 있기를 기도해 본다 :)
REF.
'Spring' 카테고리의 다른 글
| Chained Transaction Manager 파헤치기 (1) | 2023.12.09 |
|---|---|
| 실시간 코인시세 어디까지 알아봤니? part 1 (1) | 2023.08.14 |
| [Spring Boot + Chat GPT] Open AI API 적용기 (1) | 2023.04.16 |
| 분산락과 네임드락 그리고... 동시성 (1) | 2023.02.02 |
| Throttling과 debounce에 대해 알아보자 (0) | 2022.12.11 |